Deep Reinforcement Learning, DQN explained with the game of Snake.
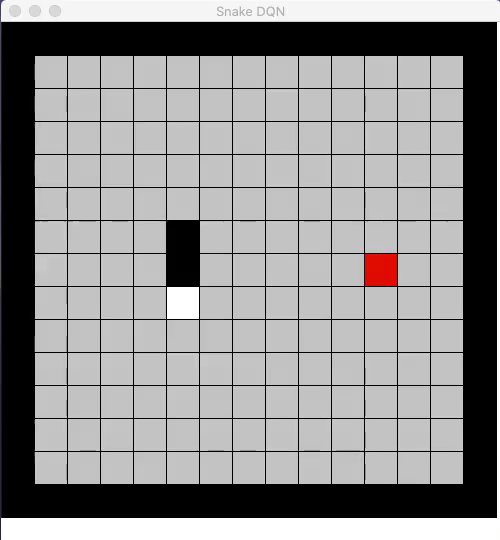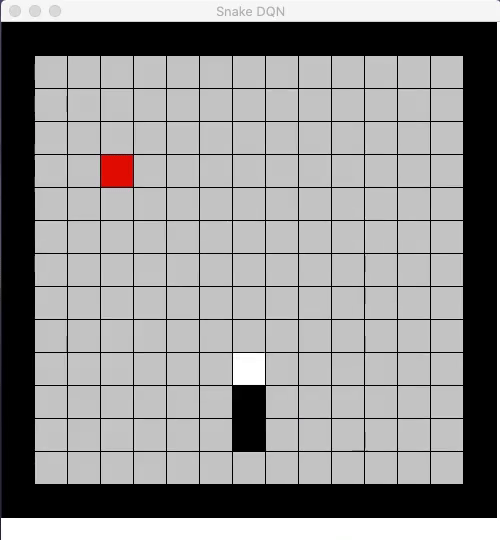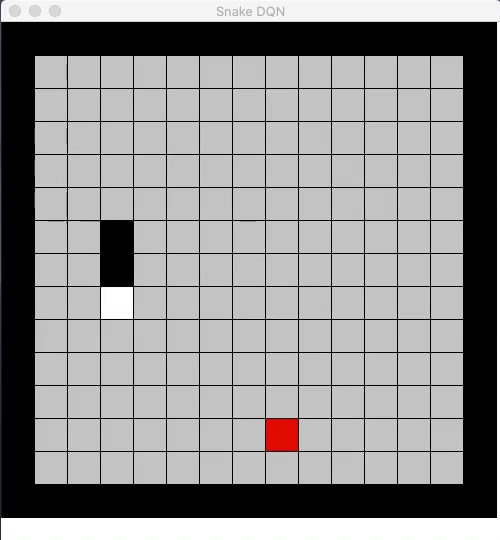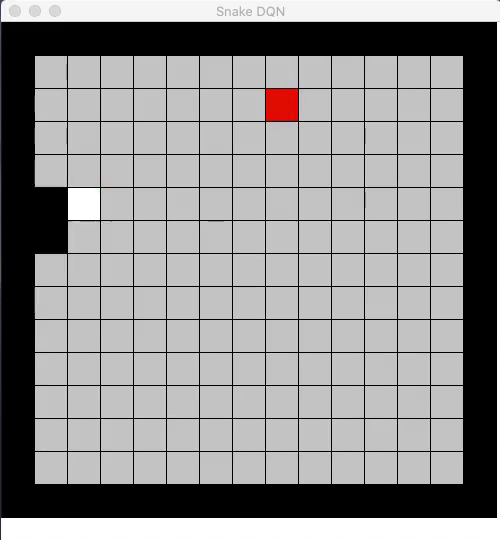
The core idea of reinforcement learning is to use rewards in a way that the AI agent can learn how to perform well by maximizing it’s expected rewards. To solve an RL problem, the AI agent forms a policy that represents what action to take at all the possible states of the environment. Classic RL approaches were limited in solving high-dimensional problems since they mostly relied on hand-crafted linear features in order to represent this policy. However, in recent years, the representation power of deep neural networks have been used in the RL problems.
An RL problem consists of one or more agents interacting with an environment. These interactions are usually considered to be episodic. So at each time step, the agents choose an action from its action space. The agent makes this decision based on the policy the agent follows and its current state. After taking action, the agents transits to a new state and receives a reward. The goal of an RL problem is to find an optimal policy that maximizes the expected overall reward. To solve an RL problem, we almost always need to calculate a value function, which approximates the value of a state or taking a specific action at that state.
TD learning is a family of algorithms that, like the Monte Carlo method, do not require the transition model of the environment. Like dynamic programming, these algorithms do not have to wait for an experience to terminate in order to update value functions. Q-learning is an off-policy variant of TD learning that follows the following update rule in order to have a good approximation of the state-action values (Q):
Deep Q-learning uses deep neural networks to approximate Q-value function from raw data. This neural network is called Deep Q-Network (DQN).
DQN is trained by minimizing the following loss for a batch of transitions:
where delta is the temporal defrence error, defined as:
Snake-RL is a python environment to train RL agents for the game of Snake! It comes with the implementation of DQN agent.
Instalation
pip install -i https://test.pypi.org/simple/ RL-Snake-mkhoshpa
Creating your agent is as easy as:
from RL_Snake import BaseAgent
import random
UP = 'up'
DOWN = 'down'
LEFT = 'left'
RIGHT = 'right'
NA = 'None'
ACTIONS = {UP:0,DOWN:1,LEFT:2,RIGHT:3,NA:4}
class RandomAgent(BaseAgent):
"""
Concrete agent class that take actions randomly
"""
def take_action(self):
"""
take actions randomly
Returns:
int or None: represent the action
"""
state = self.get_state()
if state is None:
return ACTIONS[NA]
return random.sample(ACTIONS.values(),1)
The state is two consecutive settings of the board stacked together. The provided DQN agent uses CNN to process the state and outputs the state-action values.
import torch.nn as nn
import torch.nn.functional as F
class DQN(nn.Module):
"""
"""
def __init__(self, h, w, outputs):
"""
Args:
h: height of the board
w: width of the board
outputs: number of actions
"""
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(2, 16, kernel_size=3, stride=1)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=3, stride=1)
self.bn3 = nn.BatchNorm2d(32)
# Number of Linear input connections depends on output of conv2d layers
# and therefore the input image size, so compute it.
def conv2d_size_out(size, kernel_size=3, stride=1):
return (size - (kernel_size - 1) - 1) // stride + 1
convw = conv2d_size_out(conv2d_size_out(conv2d_size_out(w)))
convh = conv2d_size_out(conv2d_size_out(conv2d_size_out(h)))
linear_input_size = convw * convh * 32
self.head = nn.Linear(linear_input_size, outputs)
# Called with either one element to determine next action, or a batch
# during optimization. Returns tensor([[left0exp,right0exp]...]).
def forward(self, x):
"""
Args:
x: Tensor representation of input states
Returns:
list of int: representing the Q values of each state-action pair
"""
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
return self.head(x.view(x.size(0), -1))
you can take a closer look at the code if you’re intrested. Please note that this in this game, the snake does not grow even when it eats an apple! References: